Meten van de lengte van je collega’s, registreren van de vraag per dag, tellen van het aantal auto’s dat per uur langskomt, steeds als je een reeks waarnemingen doet, krijg je getallen die onderling een beetje of juist veel verschillen van grootte. Je kunt die getallenreeks op verschillende manieren duiden. Een belangrijke maatstaf daarvoor is het gemiddelde: de som van alle waarnemingen gedeeld door het aantal waarnemingen. Een andere maatstaf is de modus, de meest voorkomende waarde, denk maar aan de term modaal inkomen, dat is de hoogte van het meest voorkomende inkomen. Zie de top bij klasse 3 in figuur 1. Er is nog een getal dat kenmerkend is voor een reeks: de mediaan, dat is de waarde van middelste waarneming (als je ze eerst in volgorde van waarde hebt gezet). In het voorbeeld van figuur 1, zou die waarneming de 501-de zijn en dus vallen in klasse 4.
Soms liggen alle waarnemingen dicht rondom het gemiddelde, maar soms juist niet. Er zijn maatstaven, kenmerken, om de mate uit te drukken, waarin de waarden in je reeks afwijken van het gemiddelde van die reeks. Een simpel kenmerk is de range, het verschil tussen de grootste en de kleinste waarneming. In de statistiek zul je als maatstaf voor de spreiding meestal gebruik maken van het begrip standaardspreiding of standaarddeviatie, meestal aangeduid met sigma, met het symbool s.
De standaarddeviatie (σ) geeft aan in welke mate de afzonderlijke waarnemingen afwijken van het gemiddelde. Het is de meetkundig gemiddelde afwijking. In formulevorm:
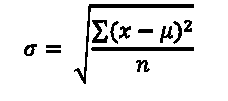
Een kort voorbeeld om het principe te verduidelijken, gebaseerd op de waarnemingen uit tabel 1 (het voorbeeld over de afwijkingen in viscositeit). Aan de tabel met klassen en aantal waarnemingen (de turflijst) voegen we 4 kolommen toe, waarin de hulpberekeningen worden uitgevoerd.
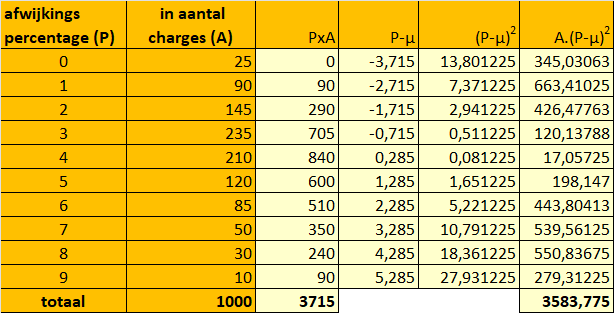
Tabel 3: hulptabel voor berekening van de standaarddeviatie
Toelichting bij tabel 3:
- Bereken het gemiddelde (μ), deel de som van alle waarden door het aantal waarden,
3715/1000 = 3,715
- Bereken per regel de verschillen tussen de klassenwaarden en μ. Dus per klasse: P-μ
- Kwadrateer per regel de berekende verschillen. Hierdoor verdwijnen de negatieve waarden: per klasse (P-μ)2
- Vermenigvuldig per regel de gevonden waarden met de aantallen per klasse: (x-μ)2
- Sommeer de kolom met alle berekeningen van A. (X-μ)2
- Bereken de variantie door het bij punt 5 gevonden totaal te delen door het aantal waarnemingen: 3583,775/1000 = 3,584
- Trek de wortel uit de variantie om de standaarddeviatie te krijgen: √3,584 = 1,89
Een paar aanvullingen:
- Je zag het al in regel 6, het kwadraat van de standaarddeviatie heet de variantie.
- Bij het berekenen van de standaarddeviatie van een kleine steekproef, is een correctie nodig. Dan gebruik je niet het aantal waarnemingen n als deler, maar n-1. De vuistregel is dat 30 of minder waarnemingen een kleine steekproef is. Om het verschil aan te geven, wordt de met (n-1) berekende standaarddeviatie meestal niet met σ aangeduid, maar met een (kleine) s.
- Naast de standaarddeviatie bestaan andere maatstaven voor de spreiding. We noemden al de range, het verschil tussen de grootste en kleinste waarneming. In de literatuur (en in oude software) kom je ook het begrip MAD tegen: de Mean Absolute Deviation. Dat is het rekenkundig gemiddelde van de afwijking. Bij alle negatieve verschillen worden de mintekens verwijderd (absolute waarden). De MAD is gemakkelijker te berekenen omdat er niet hoeft te worden gekwadrateerd en geen wortel wordt getrokken. Aan dat gemak ontleent de MAD z’n toepassing: in vroegere versies van veelgebruikte programmeertaal COBOL ontbrak de functie voor worteltrekken en de vele kwadrateringen voor berekening van σ gebruikten kostbare computertijd. De MAD heeft verder geen waarde voor de kansrekening, kan dus niet worden gebruikt voor statistisch voorraadbeheer.